# 背景:
SVN 和 Git 同样都是在特定时代下比较优秀的版本控制系统,但是随着时代的发展,SVN 越来越不能满足多人开发的需求,尤其是在多种多样,天马星空的业务场景面前,SVN 会显得力不从心。

最近在将公司的项目从 SVN 迁移到 git,踩了不少坑,所以来记录下:
因为迁移的快慢和整个仓库的大小,电脑配置有关,所以我先说下这边的情况
仓库:
仓库大概是 3.5G 左右,包含了 14500 + 的提交次数,其中包含了超过 500M 的单个文件电脑:
电脑配置就看图吧 :![]()

在以上两种情况下,排除掉采坑的时间,总耗时在 10 小时左右,当时中途我也用过一台联系 X1 的本尝试过,配置如下:

后来联想这台电脑放弃了,因为总耗时已经超过 30 小时,
# 操作:
# 1. 生成作者文件:
因为我们知道,在 SVN 上提交和在 Git 上提交对应提交者的信息展示是不同的,SVN 只会保存一个用户名,而 Git 会保存该用户的邮箱,所以我们迁移的第一步就要生成一个映射文件,将 SVN 上的用户名和其邮箱对应起来,就比如 molier = molier <[email protected]> , 转换的办法有很多,如果你团队里面的人不是很多的是时候,可以自己去提交记录中手动生成这样一个 TXT 文件
1 | XXX = XXX <XXX@XXX.com>XXX = XXX <XXX@XXX.com>.... |
但是如果,多人开发人数很多的时候,手动转很累,我们就需要一个 Atlassian 的工具包
svn-migration-scripts.jar ,通过命令拉取 SVN 仓库的用户并生成对应的开发者信息映射文件,需要 Java 运行时环境支持,大家可能还需要安装 JDK:1 | java -jar svn-migration-scripts.jar authors https://svn.example.com > authors.txt |
这样之后会在当前目录生成一个
authors.txt 文件# 2. 转换仓库
整体转换:
标准的 SVN 文件布局:
如果 SVN 仓库使用标准的了 /trunk, /branches 和 /tags 的目录结构,就可在运行命令时加上参数–stdlayout,使用如下命令1
2git svn clone --stdlayout --authors-file=authors.txt <svn-repo>/<project> <克隆到文件夹的名字>非标准的的SVN文件布局:
如果 SVN 仓库是非标准的目录布局,那就需要分别显示指定参数–trunk, –branches, –tags。1
2git svn clone --trunk=/trunk --branches=/branches --branches=/bugfixes --tags=/tags --authors-file=authors.txt <svn-repo>/<project><克隆到文件夹的名字>
部分转换:
如果仓库非常庞大的话可以选择部分转换,也就只转换指定提交之后的提交,可以试用如下代码
1
2git svn clone -r123456:HEAD --stdlayout --authors-file=authors.txt <svn-repo> <克隆到文件夹的名字>
不过这里需要注意的是如果使用这种方式来转换那么一定要指定 SVN 的代码根部,而不能指定分支,因为 SVN 的提交编号都是按照时间顺序来往下依次排列,不同的分支也可能提交编号是连续的,所以如果只关心编号的话就不能再指定分支了。以上三步中所用到的
authors.txt即为上一步所生成的,作者 -> 作者 <作者邮箱>的对应关系文件.
# 坑点
完成以上操作的话如果一切正常那么你就会获得一个新的 Git 仓库,然后就可以添加到远端,进行多人开发了,至于 git 的操作并不在本文的范围内,下面会讲一下遇到的坑以及解决办法。
# 坑点一:时间久
转换仓库是比较耗时的,因为他会一个提交一个提交的转换,转换的速度和你的仓库提交次数和电脑配置成正比,我当时转了十几个小时比较正常,而且转换完之后他还有个自己整理文件的过程也是很耗时的,不过如果你选择部分转换的话也可能很快,假如你一共 15000 个提交,然后你从 14999 来转换可能几分钟就够了。当然最好的办法就是下班前开始执行,第二天来了基本就差不多了。不过别高兴的太早,请看坑点二。
# 坑点二:垃圾过多导致暂停
因为是要遍历所有的历史提交,所以可能会有很多的无用文件 比如项目一开始代文件结构很乱,然后慢慢的经过重构,之类的优化步入正轨,这过程中必然会删掉大量的无用、冗余的文件,虽然这些文件已经不复存在了,但是提交记录会有,而且通过 git 的原理来看他还是会把这些东西一一保存下来,所以就会造成大量无用的文件越来越多,而 Git 是有一个缓冲区 (具体大小不确定) 当你无用文件把缓冲区沾满了,那么转换过程会停止会爆出如下错误
1 | Auto packing the repository in background for optimum performance. |
大概意思是垃圾太多,转移暂停让你先清理垃圾,其实只要按照他说的 进到我们转了一半的仓库 进行
git gc 就可以,但是这样一来我们就需要一直守在电脑前,随时准备输入 git gc 而且假如你下班前开始跑结果第二天上班一看跑到一半就暂停了,白白浪费了一晚上的时间,真的会崩溃的。所以通过 google 找到了解决办法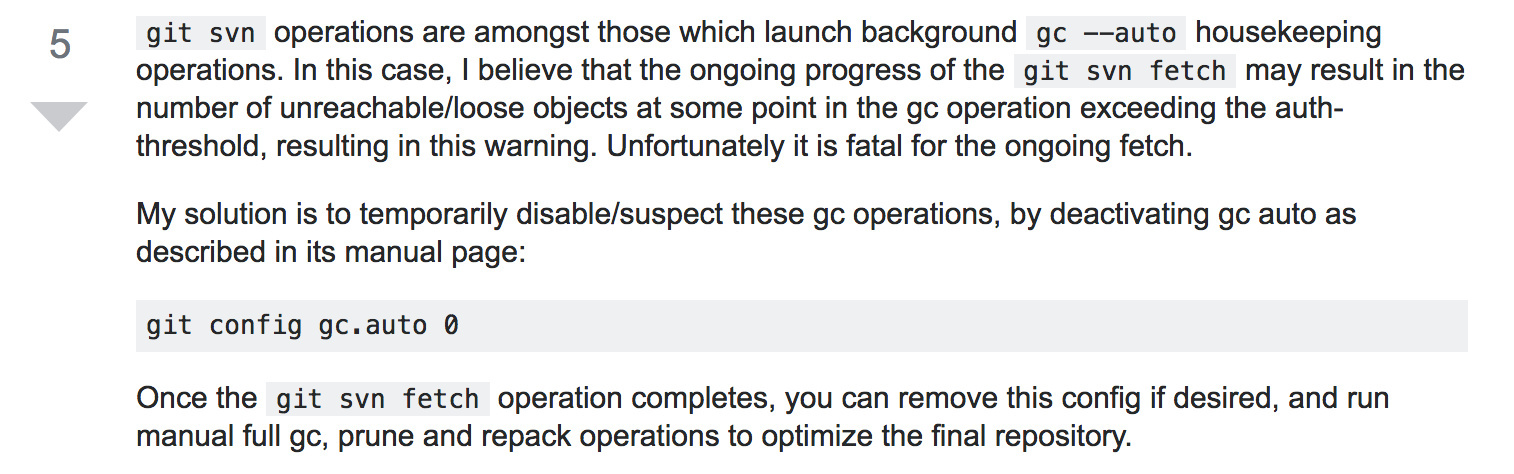
也就是开始转换的时候先进入仓库输入 git config gc.auto 0 关闭 gc 功能,然后就可以一直跑到黑了,你大可以放心的运行命令然后下班回家。不过还有一点需要注意的是垃圾文件是否过多和你仓库大小没有太大关系,及时你仓库提交不多,但是每次提交都有很大改动的话也还是会出现这个问题,所以这里建议不管你仓库多大,都要先进行一下这个操作,以防万一。
# 坑点三:大文件处理
git 和 SVN 不同,在 git 上提交的单个文件是有大小限制的,超过这个大小就不允许提交到仓库中,通常我们会用 git LFS 来解决,具体的安装,添加步骤网上大把的教程,就不在这里说,不过他只会告诉你大文件的大小和限制的大小,具体的大文件是哪个他不会告诉你,这里可以用以下命令查看
1 | git ls-tree -r -t -l --full-name HEAD | sort -n -k 4 | tail -n 10 //查找git 仓库中排名前十的大文件(升序) |
他会输出前十个最大的文件,然后你再按需处理。但是当你把大文件添加到 LFS 中后再次推送还是会爆出同样的错误,而且还是同样的文件,也就是说你根本没添加成功,其实并不是这样的,在添加 LFS 中只要你操作没错,就是添加成功了,他还会报错的原因是因为虽然你工程中的大文件已经添加,但是你的历史提交记录中是包含大文件的代码快照的,所以你需要将历史上所有包含大文件的提交记录重写,删掉大文件相关的东西,git 中重写 commit 的命令是:
1 | git filter-branch --force --index-filter 'git rm -rf --cached --ignore-unmatch 你大文件所在的目录' --prune-empty --tag-name-filter cat -- --all |
这个过程也比较漫长,他会便利你所有的提交记录并一一修改,不过就是漫长的等待就可以了,等到完成之后我们需要将代码 push 到远端,因为我们修改了所有的 commit 我们需要强制 push 使用如下命令
1 | git push origin master --force |
# 坑点四:打包时间过长
再上一步我们执行完推送命令的时候,会先进行文件打包处理,这个过程也是非常漫长,而且非常消耗电脑资源的,按照我的电脑配置来说,这个过程一旦开始,电脑基本就是内存、cpu 全满的状态,鼠标也没法动,所以这个过程要有心理准备。漫长的等待之后就推送成功了。